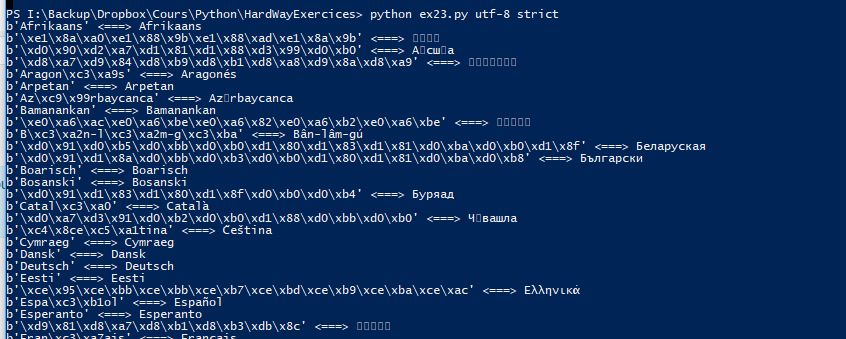
I’m doing Exercise 23 on python 3 and I see squares for some line after " <===> " instead of the word in different language.
Exemple: (I have put “+” because I can’t reproduce the square … So first line is fine but second have those square)
PS I:\Backup\Dropbox\Cours\Python\HardWayExercices> python ex23.py utf-8 strict
b’Afrikaans’ <===> Afrikaans
b’\xe1\x8a\xa0\xe1\x88\x9b\xe1\x88\xad\xe1\x8a\x9b’ <===> ++++
*I have upload the result too
I use PowerShell in windows 10 … I have search on the web and try couple of thing to turn PowerShell into utf-8 but It doesn’t work.
That’s normal. To make it work in PowerShell requires a lot of weird installs of different fonts. However, apparently it’ll work in cmd.exe. In the video you see me trying to get it to work and I still can’t. Try with cmd.exe and let me know what you find.
Maybe someone could try PowerShell ISE? I have read it has more fonts.
I’ve tried running this exercise there, but it didn’t run like it did in PowerShell.
I have no idea why, because I don’t know a lot about software/programming yet.
Finally, I just download a third party windows terminal emulator name Cmder and it work now, I see all the character of all language, no more stupid square!
I’m like that, I can’t continue when there is something not working. Now I’ll get back to understand this code!
Looks interesting, it appear that this is built on (or continues on) the terminal / console emulator ConEmu. We had used ConEmu in the past with Win7 and it worked fairly well.
So what Zed shown on the pdf I will need to see the exact same output then it means we did it right?
I can see some weired charcters when I run it in power shell.
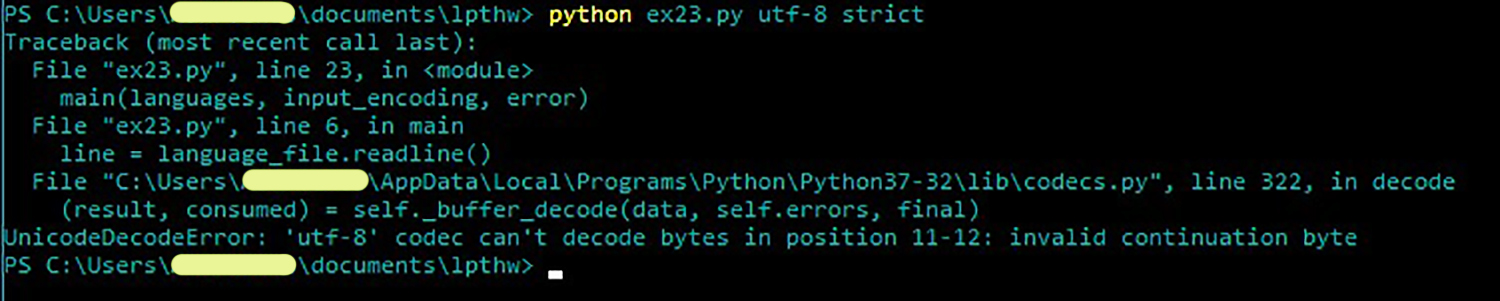
I am also having this issue, it’s very frustrating! By chance have you or anyone found a solution? Attached is my error code. I believe they are the same, but I’m not 100% sure.
Edit:
Okay so anyone who might still be having issues with this, the problem for me was that I had copied the language file into a text file and named it languages.txt instead of downloading it. You have to download the language file for it to work. CTRL-S will work when the pdf redirects you to the web page with the text.