So I’ve checked the py-file and tried downloading the txt-file from different browsers and still I get this error.
I haven’t found this error on the forum so far so I made this thread.
Thanks!
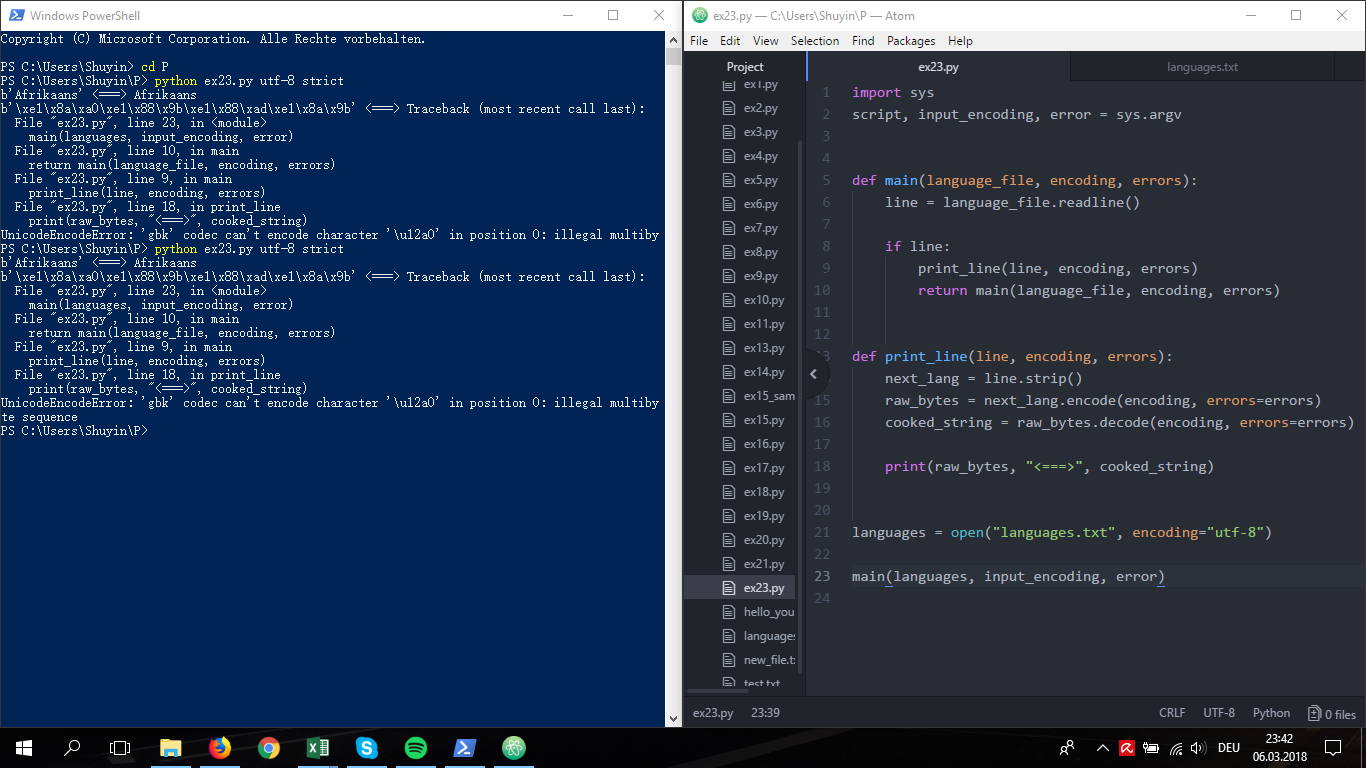
b'\xe1\x8a\xa0\xe1\x88\x9b\xe1\x88\xad\xe1\x8a\x9b' <===> Traceback (most recent call last):
File "ex23.py", line 23, in <module>
main (languages, input_encoding, error)
File "ex23.py", line 9, in main
print_line(line, encoding, errors)
File "ex23.py", line 18, in print_line
print(raw_bytes, "<===>", cooked_string)
UnicodeEncodeError: 'gbk' codec can't encode character '\u12a0' in position 0: illegal multibyte sequence
That’s a super weird error. Are you on Windows by chance? I’m going to guess maybe Windows 7 and your codec is set to GBK, so by default I think the file is converted but I’m not exactly sure. Can you post a screenshot of right when you have this error, and also, use the right-click Save As… to save the file exactly.
So I’m going to guess that your PowerShell is set to use gbk, but Python is trying to output convert the output but that causes problems. I’d say you’ve done enough on this exercise and can move on. Fixing this might take way too much, and then just remember that you have this error when you output utf-8. Now, if you want to try to fix it then you’d have to see if you can make PowerShell recognize utf-8 output. I’m not exactly sure how you’d do that though.