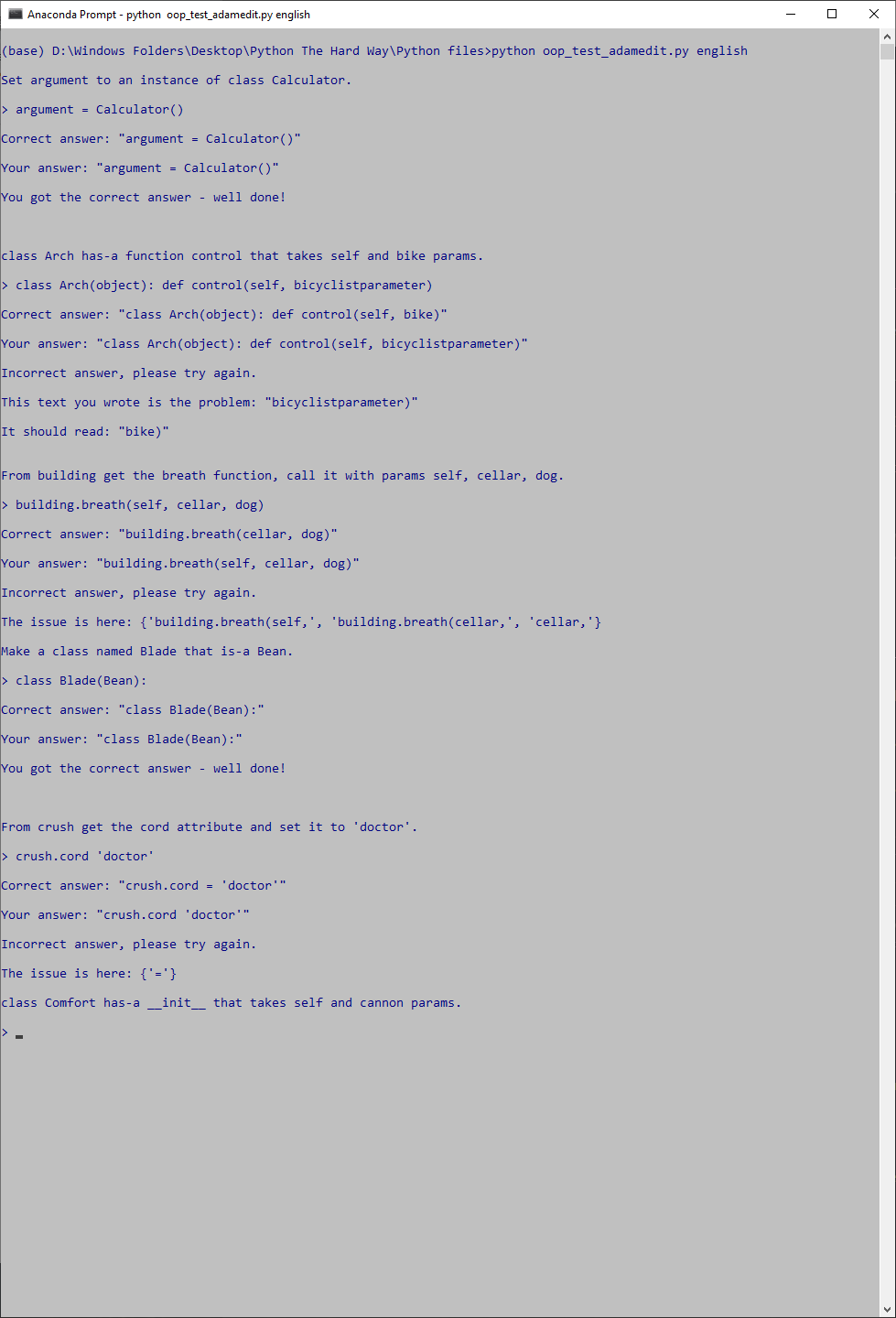
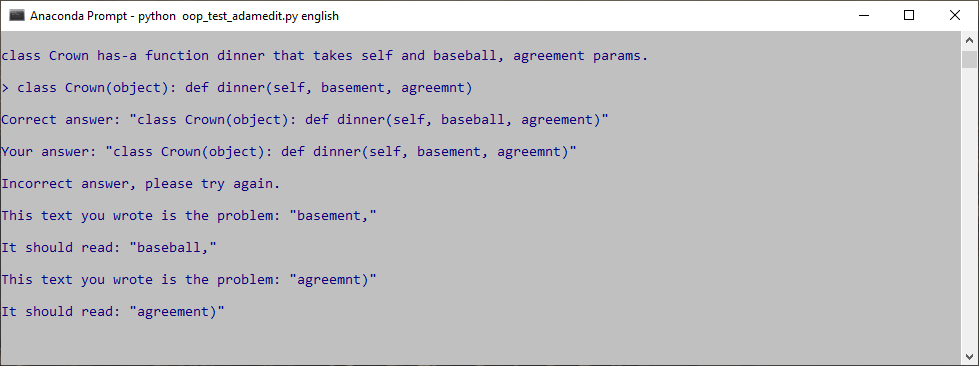
Fixed - thank you for helping me get better at writing comprehensible code.
I’ve adopted some notation conventions in my naming; if there’s a better method for me to use, please let me know, this is something I want to make sure I have good habits about.
This lead me down quite the rabbit hole. During my journey of discovery I learned all kinds of new things, from how format() works to format_map(), to the fact that dictionaries have a uniqueness requirement upon their keys (which seems completely reasonable and intuitive now that I write it down).
From what I can tell, str.format(**dict_name) seems to me to be functionally equivalent to str.format_map(dict_name) - but as a newb, I am likely missing something important here - please let me know!
I am also interested in any critique anyone has on how I’ve gone about updating the code.
Something I am a bit unsure about: I felt it necessary to put a number after each instance of @@@ / *** / %%% in the PHRASES strings as otherwise it seemed every instance of the string was replaced with the dictionary item, not just the first instance. Perhaps this is a difference between str.format(**dict_name) and str.format_map(dict_name)? I have not yet tested with both methods and I did use format_map() for my initial development.
Regardless, thank you for sending me on this quest of knowledge @zedshaw - it has been a fascinating exploration.
I’ve kept the debugging print statements I used in this version of my code:
import random
from urllib.request import urlopen
import sys
WORD_URL = "http://learncodethehardway.org/words.txt"
WORDS = []
PHRASES = {
"class {%%%0}({%%%1}):":
"Make a class named {%%%0} that is-a {%%%1}.",
"class {%%%0}(object):\n\tdef __init__(self, {***0})" :
"class {%%%0} has-a __init__ that takes self and {***0} params.",
"class {%%%0}(object):\n\tdef {***0}(self, {@@@0})":
"class {%%%0} has-a function {***0} that takes self and {@@@0} params.",
"{***0} = {%%%0}()":
"Set {***0} to an instance of class {%%%0}.",
"{***0}.{***1}({@@@0})":
"From {***0} get the {***1} function, call it with params self, {@@@0}.",
"{***0}.{***1} = '{***2}'":
"From {***0} get the {***1} attribute and set it to '{***2}'."
}
# do they want to drill phrases first
if len(sys.argv) == 2 and sys.argv[1] == "english":
PHRASE_FIRST = True
else:
PHRASE_FIRST = False
# load up the words from the website
for word in urlopen(WORD_URL).readlines():
WORDS.append(str(word.strip(), encoding="utf-8"))
# The convert function has been deprecated
# Do not use without updating to take into account the numbers added to PHRASES strings.
def convert(snippet, phrase):
class_names = [w.capitalize() for w in
random.sample(WORDS, snippet.count("%%%"))]
other_names = random.sample(WORDS, snippet.count("***"))
results = []
param_names = []
for i in range(0, snippet.count("@@@")):
param_count = random.randint(1,3)
param_names.append(', '.join(
random.sample(WORDS, param_count)))
for sentence in snippet, phrase:
# this is how you duplicate a list or string
result = sentence[:]
# fake class names
for word in class_names:
result = result.replace("{%%%}", word, 1)
# fake other names
for word in other_names:
result = result.replace("{***}", word, 1)
# fake parameter lists
for word in param_names:
result = result.replace("{@@@}", word, 1)
results.append(result)
print(f"The results: {results}")
return results
# New code begins here. Defining functions...
def convert_version2(cv2_snippet, cv2_phrase):
cv2_class_names = [q.capitalize() for q in
random.sample(WORDS, cv2_snippet.count("%%%"))]
cv2_other_names = random.sample(WORDS, cv2_snippet.count("***"))
cv2_results = []
cv2_param_names = []
cv2_the_dict = dict()
for i in range(0, cv2_snippet.count("@@@")):
cv2_param_count = random.randint(1,3)
cv2_param_names.append(', '.join(
random.sample(WORDS, cv2_param_count)))
for cv2_sentence in cv2_snippet, cv2_phrase:
cv2_result = cv2_sentence[:]
print(f"cv2_snippet: {cv2_snippet}")
print(f"cv2_phrase: {cv2_phrase}")
print(f"The cv2_class_names: {cv2_class_names}")
print(f"The cv2_other_names: {cv2_other_names}")
print(f"The cv2_param_names: {cv2_param_names}")
counter = 0
for word in cv2_class_names:
print(f"The word: {word}")
print(f"The counter: {counter}")
the_key = f"%%%{counter}"
print(f"The key: {the_key}")
cv2_the_dict.update({the_key: word})
print(f"The dict: {cv2_the_dict}")
counter = counter + 1
counter = 0
for word in cv2_other_names:
print(f"The word: {word}")
print(f"The counter: {counter}")
the_key = f"***{counter}"
print(f"The key: {the_key}")
cv2_the_dict.update({the_key: word})
print(f"The dict: {cv2_the_dict}")
counter = counter + 1
counter = 0
for word in cv2_param_names:
print(f"The word: {word}")
print(f"The counter: {counter}")
the_key = f"@@@{counter}"
print(f"The key: {the_key}")
cv2_the_dict.update({the_key: word})
print(f"The dict: {cv2_the_dict}")
counter = counter + 1
print(f"The result: {cv2_result}")
# This works.
cv2_result = cv2_result.format(**cv2_the_dict)
# But this also works.
# cv2_result = cv2_result.format_map(cv2_the_dict)
print(f"The updated result: {cv2_result}")
cv2_results.append(cv2_result)
print(f"The cv2_results: {cv2_results}")
return cv2_results
def equalize_list_lengths(ell_input_list, ell_stripped_list):
if len(ell_input_list) == len(ell_stripped_list):
return 1
elif len(ell_input_list) > len(ell_stripped_list):
while len(ell_input_list) != len(ell_stripped_list):
ell_stripped_list.append(' ')
elif len(ell_stripped_list) > len(ell_input_list):
while len(ell_stripped_list) != len(ell_input_list):
ell_input_list.append(' ')
else:
print("You should never see this message.")
incorrect_answer(ell_input_list, ell_stripped_list)
def incorrect_answer(ia_input_list, ia_stripped_list):
if len(ia_input_list) == len(ia_stripped_list):
print("\nIncorrect answer, please try again.\n")
# Goal is to show the user where they got the answer wrong.
# If the two lists have identical length,
# then iteratively compare each item (string) in the list
# and print out the user input when they are different.
# Print both the correct answer and the user input.
print(f"Correct answer: \"{stripped_answer}\"")
print(f"Your answer: \t\"{user_input}\"\n")
for i in range(len(ia_input_list)):
if ia_input_list[i] != ia_stripped_list[i]:
print(f"This text you wrote is a problem: \t\"{ia_input_list[i]}\"")
print(f"The text should read: \t\t\t\"{ia_stripped_list[i]}\"\n")
else:
equalize_list_lengths(ia_input_list, ia_stripped_list)
# keep going until they hit CTRL-D
try:
while True:
snippets = list(PHRASES.keys())
random.shuffle(snippets)
for snippet in snippets:
phrase = PHRASES[snippet]
question, answer = convert_version2(snippet, phrase)
if PHRASE_FIRST:
question, answer = answer, question
print(f"\n{question}")
# Set the user input to a variable.
user_input = input("\n> ")
# Create a variable to hold the correct answer without tabs or line feeds.
# Done because I think the user input won't have either of these.
stripped_answer = answer.replace('\n', ' ').replace('\t', '')
# First we're creating lists to hold the correct answer
# and the user input strings parsed on spaces.
user_input_list = user_input.split()
stripped_answer_list = stripped_answer.split()
# Comparing the variables; the correct answer and what user input.
if user_input != stripped_answer:
incorrect_answer(user_input_list, stripped_answer_list)
else:
print("\nYou got the correct answer - well done!\n")
except EOFError:
print("\nBye")
And I’ve removed the debug print statements from this one:
import random
from urllib.request import urlopen
import sys
WORD_URL = "http://learncodethehardway.org/words.txt"
WORDS = []
PHRASES = {
"class {%%%0}({%%%1}):":
"Make a class named {%%%0} that is-a {%%%1}.",
"class {%%%0}(object):\n\tdef __init__(self, {***0})" :
"class {%%%0} has-a __init__ that takes self and {***0} params.",
"class {%%%0}(object):\n\tdef {***0}(self, {@@@0})":
"class {%%%0} has-a function {***0} that takes self and {@@@0} params.",
"{***0} = {%%%0}()":
"Set {***0} to an instance of class {%%%0}.",
"{***0}.{***1}({@@@0})":
"From {***0} get the {***1} function, call it with params self, {@@@0}.",
"{***0}.{***1} = '{***2}'":
"From {***0} get the {***1} attribute and set it to '{***2}'."
}
# do they want to drill phrases first
if len(sys.argv) == 2 and sys.argv[1] == "english":
PHRASE_FIRST = True
else:
PHRASE_FIRST = False
# load up the words from the website
for word in urlopen(WORD_URL).readlines():
WORDS.append(str(word.strip(), encoding="utf-8"))
# The convert function has been deprecated
# Do not use without updating to take into account the numbers added to PHRASES strings.
def convert(snippet, phrase):
class_names = [w.capitalize() for w in
random.sample(WORDS, snippet.count("%%%"))]
other_names = random.sample(WORDS, snippet.count("***"))
results = []
param_names = []
for i in range(0, snippet.count("@@@")):
param_count = random.randint(1,3)
param_names.append(', '.join(
random.sample(WORDS, param_count)))
for sentence in snippet, phrase:
# this is how you duplicate a list or string
result = sentence[:]
# fake class names
for word in class_names:
result = result.replace("{%%%}", word, 1)
# fake other names
for word in other_names:
result = result.replace("{***}", word, 1)
# fake parameter lists
for word in param_names:
result = result.replace("{@@@}", word, 1)
results.append(result)
print(f"The results: {results}")
return results
# New code begins here. Defining functions...
def convert_version2(cv2_snippet, cv2_phrase):
cv2_class_names = [q.capitalize() for q in
random.sample(WORDS, cv2_snippet.count("%%%"))]
cv2_other_names = random.sample(WORDS, cv2_snippet.count("***"))
cv2_results = []
cv2_param_names = []
cv2_the_dict = dict()
for i in range(0, cv2_snippet.count("@@@")):
cv2_param_count = random.randint(1,3)
cv2_param_names.append(', '.join(
random.sample(WORDS, cv2_param_count)))
for cv2_sentence in cv2_snippet, cv2_phrase:
cv2_result = cv2_sentence[:]
counter = 0
for word in cv2_class_names:
the_key = f"%%%{counter}"
cv2_the_dict.update({the_key: word})
counter = counter + 1
counter = 0
for word in cv2_other_names:
the_key = f"***{counter}"
cv2_the_dict.update({the_key: word})
counter = counter + 1
counter = 0
for word in cv2_param_names:
the_key = f"@@@{counter}"
cv2_the_dict.update({the_key: word})
counter = counter + 1
# This works.
cv2_result = cv2_result.format(**cv2_the_dict)
# But this also works.
# cv2_result = cv2_result.format_map(cv2_the_dict)
cv2_results.append(cv2_result)
return cv2_results
def equalize_list_lengths(ell_input_list, ell_stripped_list):
if len(ell_input_list) == len(ell_stripped_list):
return 1
elif len(ell_input_list) > len(ell_stripped_list):
while len(ell_input_list) != len(ell_stripped_list):
ell_stripped_list.append(' ')
elif len(ell_stripped_list) > len(ell_input_list):
while len(ell_stripped_list) != len(ell_input_list):
ell_input_list.append(' ')
else:
print("You should never see this message.")
incorrect_answer(ell_input_list, ell_stripped_list)
def incorrect_answer(ia_input_list, ia_stripped_list):
if len(ia_input_list) == len(ia_stripped_list):
print("\nIncorrect answer, please try again.\n")
# Goal is to show the user where they got the answer wrong.
# If the two lists have identical length,
# then iteratively compare each item (string) in the list
# and print out the user input when they are different.
# Print both the correct answer and the user input.
print(f"Correct answer: \"{stripped_answer}\"")
print(f"Your answer: \t\"{user_input}\"\n")
for i in range(len(ia_input_list)):
if ia_input_list[i] != ia_stripped_list[i]:
print(f"This text you wrote is a problem: \t\"{ia_input_list[i]}\"")
print(f"The text should read: \t\t\t\"{ia_stripped_list[i]}\"\n")
else:
equalize_list_lengths(ia_input_list, ia_stripped_list)
# keep going until they hit CTRL-D
try:
while True:
snippets = list(PHRASES.keys())
random.shuffle(snippets)
for snippet in snippets:
phrase = PHRASES[snippet]
question, answer = convert_version2(snippet, phrase)
if PHRASE_FIRST:
question, answer = answer, question
print(f"\n{question}")
# Set the user input to a variable.
user_input = input("\n> ")
# Create a variable to hold the correct answer without tabs or line feeds.
# Done because I think the user input won't have either of these.
stripped_answer = answer.replace('\n', ' ').replace('\t', '')
# First we're creating lists to hold the correct answer
# and the user input strings parsed on spaces.
user_input_list = user_input.split()
stripped_answer_list = stripped_answer.split()
# Comparing the variables; the correct answer and what user input.
if user_input != stripped_answer:
incorrect_answer(user_input_list, stripped_answer_list)
else:
print("\nYou got the correct answer - well done!\n")
except EOFError:
print("\nBye")